怎样用python requests库爬取一个网页的页面
1、首先需要打开python的ide,这里以python自带的idle为例子来说明。
2、打开之后,导入requests库

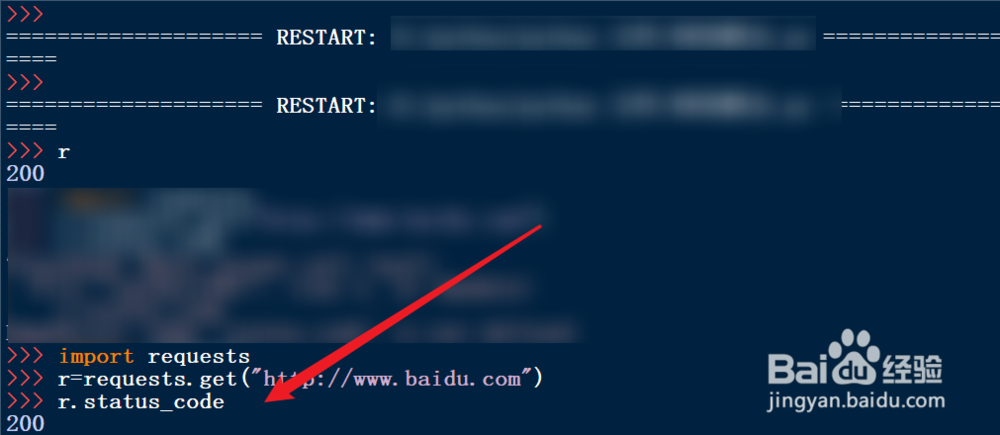
3、使用get()方法获取你需要访问的页面

4、访问的状态码,如果为200,这说明访问成功
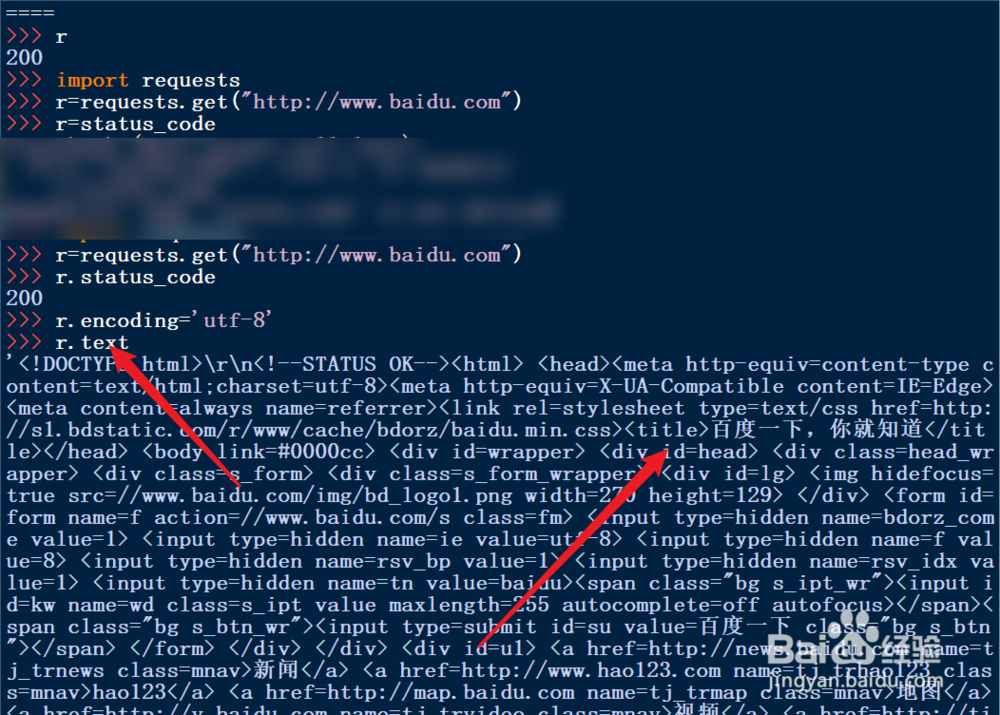
5、更改编码

6、然后页面也可以获取了
阅读量:23
阅读量:161
阅读量:32
阅读量:110
阅读量:26
1、首先需要打开python的ide,这里以python自带的idle为例子来说明。
2、打开之后,导入requests库
3、使用get()方法获取你需要访问的页面
4、访问的状态码,如果为200,这说明访问成功
5、更改编码
6、然后页面也可以获取了